
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CC BY 4.0 (除特别声明或转载文章外)
显卡上的规约操作是一个经典优化案例。在网上能找到的大部分实现中,性能比较优秀的是使用 Shared Memory 并进行访存优化的树形规约。
近期正好在做这方面的一些优化,同时了解到从 CUDA 9.0 开始,CUDA 引入了更加灵活的 Warp 操作原语,这一方面使得 CUDA 编程更加简单,一方面也使得一些原有的功能发生了一些改变。本文重点对 Warp 和 Shared Memory 两种方法实现的并行规约操作进行性能对比。
实验环境
使用 v100 集群上一个结点的单张 v100 运行。
$ nvdia-smi
Mon Dec 2 08:38:49 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.48 Driver Version: 410.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:3B:00.0 Off | 0 |
| N/A 30C P0 24W / 250W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
实验过程与分析
前提条件
为了简化代码,这里我使用 <thrust/device_vector.h> 库进行内存管理。虽然 <thrust> 库对底层代码做了更高级的抽象,但在本例中的开销却几乎可以忽略(已经和手动 cudaMalloc 的代码进行对比验证)。
此外,在显卡上进行区间规约时,为了避免加读写锁或者原子操作,通常不直接把所有的结果归约到同一个内存地址。取而代之的,是使用多级规约,通过多次启动核函数,在几乎没有增加多少访存的前提下大大增加了线程的效率。然而,在这里我只是想对 Shared Memory 和 Warp Shuffle 访存的性能进行对比,而时间大头其实都在第一层规约上。二级之后的规约偷个懒用thrust::reduce代替之(其实应该多次启动自己的核函数,但是我太懒了)。由于二级及之后的规约时间其实是可以忽略不计的,因此在本例中是完全可行的。
使用 Shared Memory
虽然不是文章重点,但我还是觉得有必要复习一下 Shared Memory 上进行 Reduce 的一些 Trick 操作。
- 使用
template这是为了让接下来的循环for (size_t offset = BLOCK_SIZE >> 1; offset > 0; offset >>= 1)可以被编译器自动展开优化。如果直接使用blockDim.x的话,既不能让编译器展开循环,也不能用作声明shared[]大小。 - 对 reduce 过程中的访存进行优化:
if (reduce_id < offset) shared[threadIdx.x] += shared[threadIdx.x ^ offset];,这里访存的时候相邻线程访问相邻的地址,也没有 conflict。(访存的原理图和下面 Warp 的那张很类似,这里就不放出了) - 官方的代码还有一些比较给劲的优化策略(见文末的参考),如 Completely Unrolled、Multiple Adds。但是这些策略都比较暴力,且不是本文重点,不方便和 Warp 进行比较,我这里就没有做了。
template <size_t BLOCK_SIZE>
void __global__ shared_asum_kernel(
const size_t n,
const unsigned *src_d,
unsigned *tmp_d)
{
const size_t
global_id = threadIdx.x + blockDim.x * blockIdx.x;
unsigned __shared__ shared[BLOCK_SIZE];
shared[threadIdx.x] = src_d[global_id];
for (size_t offset = BLOCK_SIZE >> 1; offset > 0; offset >>= 1)
{
__syncthreads();
if (threadIdx.x < offset)
shared[threadIdx.x] += shared[threadIdx.x ^ offset];
}
if (threadIdx.x == 0)
tmp_d[global_id / BLOCK_SIZE] = shared[threadIdx.x];
}
运行时间为15.728032ms。
使用 Warp
Warp 级别的操作原语(Warp-level Primitives)通过 shuffle 指令,允许 thread 直接读其他 thread 的寄存器值,只要两个 thread 在同一个 warp 中,这种比通过 shared Memory 进行 thread 间的通讯效果更好,latency 更低,同时也不消耗额外的内存资源来执行数据交换。可以看到,和使用 Shared Memory 的代码长得非常相似,只是BLOCK_SIZE换成了WARP_SIZE,threadIdx.x换成了lane_id。
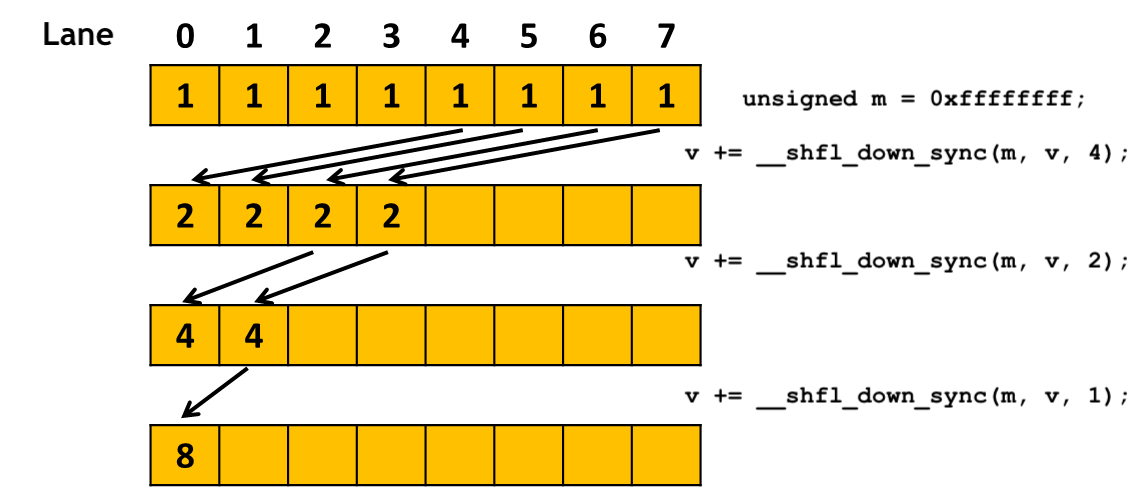
此外,我用__shfl_xor_sync而不是__shfl_down_sync,这样实现的不仅仅是树形规约,还是一个蝶形规约!并且通信步数并没有增加~
template <size_t WARP_SIZE>
void __global__ warp_asum_kernel(
const size_t n,
const unsigned *src_d,
unsigned *tmp_d)
{
const size_t
global_id = threadIdx.x + blockDim.x * blockIdx.x,
lane_id = global_id % WARP_SIZE;
unsigned
val = global_id < n ? src_d[global_id] : 0;
for (size_t offset = WARP_SIZE >> 1; offset > 0; offset >>= 1)
val += __shfl_xor_sync(0xffffffff, val, offset, WARP_SIZE);
if (lane_id == 0)
tmp_d[global_id / WARP_SIZE] = val;
}
运行时间达到了7.712928ms,轻松提高了一倍多的计算性能!同时也不难发现,使用 Warp 操作原语的代码更简洁,同时也移除了对 Shared Memory 的依赖,可以说是非常棒了!
源代码与运行结果
asum.pbs
调度脚本。
#PBS -N Dasum
#PBS -l nodes=1:ppn=32:gpus=1
#PBS -j oe
#PBS -q gpu
source /public/software/profile.d/cuda10.0.sh
cd $PBS_O_WORKDIR
nvcc asum.cu -run
asum.o18854
运行结果。
1073741824 : 5.524512ms elapsed.
1073741824 : 15.728032ms elapsed.
1073741824 : 7.712928ms elapsed.
第一行是使用 thrust::reduce 库的结果,作为两种优化方案的标杆。可以看到,thrust 库能够号称「Code at the speed of light」,还是做了很多优化的。
asum.cu
#include <stdio.h>
#include <cuda_runtime.h>
#include <thrust/device_vector.h>
#include <thrust/reduce.h>
template <size_t BLOCK_SIZE>
void __global__ shared_asum_kernel(
const size_t n,
const unsigned *src_d,
unsigned *tmp_d)
{
const size_t
global_id = threadIdx.x + blockDim.x * blockIdx.x;
unsigned __shared__ shared[BLOCK_SIZE];
shared[threadIdx.x] = src_d[global_id];
for (size_t offset = BLOCK_SIZE >> 1; offset > 0; offset >>= 1)
{
__syncthreads();
if (threadIdx.x < offset)
shared[threadIdx.x] += shared[threadIdx.x ^ offset];
}
if (threadIdx.x == 0)
tmp_d[global_id / BLOCK_SIZE] = shared[threadIdx.x];
}
template <size_t WARP_SIZE>
void __global__ warp_asum_kernel(
const size_t n,
const unsigned *src_d,
unsigned *tmp_d)
{
const size_t
global_id = threadIdx.x + blockDim.x * blockIdx.x,
lane_id = global_id % WARP_SIZE;
unsigned
val = global_id < n ? src_d[global_id] : 0;
for (size_t offset = WARP_SIZE >> 1; offset > 0; offset >>= 1)
val += __shfl_xor_sync(0xffffffff, val, offset, WARP_SIZE);
if (lane_id == 0)
tmp_d[global_id / WARP_SIZE] = val;
}
int main()
{
const size_t
n = 1 << 30,
BLOCK_SIZE = 1 << 10,
WARP_SIZE = 1 << 5,
REDUCE_SIZE = (n + WARP_SIZE - 1) / WARP_SIZE;
thrust::device_vector<unsigned> src(n, 1), tmp(REDUCE_SIZE);
for (int op = 0; op < 3; ++op)
{
unsigned sum;
cudaEvent_t beg, end;
cudaEventCreate(&beg);
cudaEventCreate(&end);
cudaEventRecord(beg, 0);
if (op == 0)
sum = thrust::reduce(src.begin(), src.begin() + n);
if (op == 1)
{
shared_asum_kernel<
BLOCK_SIZE><<<
(n + BLOCK_SIZE - 1) / BLOCK_SIZE,
BLOCK_SIZE>>>(
n,
thrust::raw_pointer_cast(src.data()),
thrust::raw_pointer_cast(tmp.data()));
sum = thrust::reduce(tmp.begin(), tmp.begin() + (n + BLOCK_SIZE - 1) / BLOCK_SIZE);
}
if (op == 2)
{
warp_asum_kernel<
WARP_SIZE><<<
(n + BLOCK_SIZE - 1) / BLOCK_SIZE,
BLOCK_SIZE>>>(
n,
thrust::raw_pointer_cast(src.data()),
thrust::raw_pointer_cast(tmp.data()));
sum = thrust::reduce(tmp.begin(), tmp.begin() + (n + WARP_SIZE - 1) / WARP_SIZE);
}
cudaEventRecord(end, 0);
cudaEventSynchronize(beg);
cudaEventSynchronize(end);
float elapsed_time;
cudaEventElapsedTime(
&elapsed_time,
beg,
end);
printf("%u : %fms elapsed.\n", sum, elapsed_time);
}
}